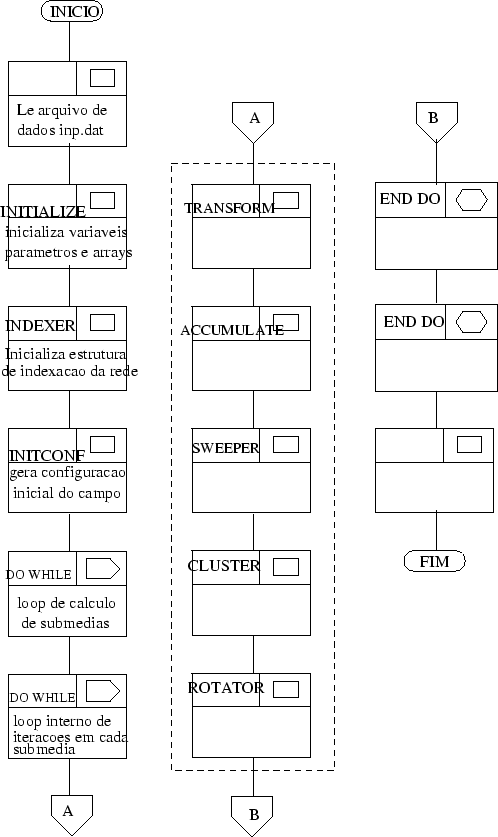
Os programas mcrelaxer e mcsampler geram as configurações do campo para acúmulo dos observáveis. A estrutura geral dos dois programas é a mesma, mas eles apresentam algumas diferenças relacionadas com as suas necessidades específicas. Existem dois loops centrais. O externo está relacionado com a quantidade de submédias desejadas para o cálculo estatístico (naver). O mais interno está relacionado com o número de iterações efetuadas em cada uma das submédias (niter). Os valores destas duas variáveis encontram-se no arquivo inp.dat.
O programa mcrelaxer tem como objetivo gerar, a
partir de uma configuração inicial dos campos, escolhida
arbitrariamente na rede, uma configuração dos campos relaxada,
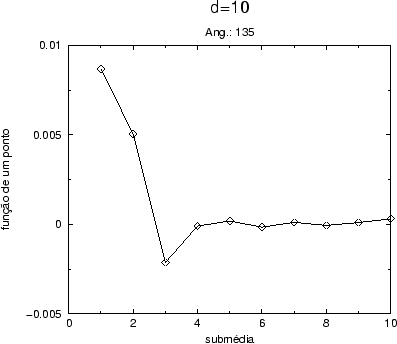
necessária para a tomada dos dados. Um forma de medir a relaxação do
campo é olhando para a função de um ponto
![]() ,
que
deve ser constante para um campo relaxado. A figura (B.1) ilustra
este comportamento.
,
que
deve ser constante para um campo relaxado. A figura (B.1) ilustra
este comportamento.
 |
Como este programa é relativamente rápido não é preciso nenhuma forma de paralelização.
O programa mcsampler gera, a partir de uma configuração relaxada do campo, as configurações necessárias para a medida dos observáveis. Assim sendo, ele é bem mais demorado que o mcrelaxer e torna-se, portanto, importante o uso de paralelização. Esta é uma diferença básica entre os dois programas.
A estrutura geral dos dois códigos é apresentada na figura (B.2).
A subrotina initialize, como o próprio nome já diz, inicializa
alguns parâmetros, como o valor de ![]() ,
o seu dobro, o valor do
momento na rede (mplatt), entre outros. A rotina também inicializa
alguns flags relacionados com a dimensionalidade da rede e
principalmente, guarda em matrizes as fases da transformada de Fourier
do campo para o espaço de momentos.
,
o seu dobro, o valor do
momento na rede (mplatt), entre outros. A rotina também inicializa
alguns flags relacionados com a dimensionalidade da rede e
principalmente, guarda em matrizes as fases da transformada de Fourier
do campo para o espaço de momentos.
Para calcular as transformadas de Fourier do campo
![]() ,
precisamos calcular expressões do tipo
,
precisamos calcular expressões do tipo
Os cossenos são armazenados na matriz phase() e os senos na
matriz phaux(). Note que
![]() assume valores entre
-dN2/2 e +dN2/2, porém sem percorrer todos os seus inteiros. Por
simplicidade de código armazenamos somente as componentes positivas
destas fases.
assume valores entre
-dN2/2 e +dN2/2, porém sem percorrer todos os seus inteiros. Por
simplicidade de código armazenamos somente as componentes positivas
destas fases.
A subrotina indexer lineariza a rede d-dimensional preservando porém a estrutura de vizinhos, utilizada nos algoritmos de geração do campo. Os sítios são classificados em black e white como em um tabuleiro de xadrez.
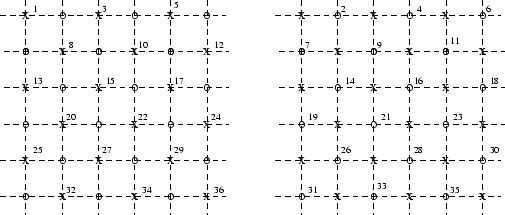
Como exemplo vamos considerar uma rede com d=2 e N=6. A rede é indexada através do índice ind, indo de 1 a 36, conforme a figura (B.3).
Os sítios com círculo são ditos white e os com cruzes, black. São criadas duas estruturas de indexação auxiliares (fig. (B.4)) expressas através de dois vetores: indwhite() e indblack(). Neste caso, portanto, temos indwhite(1)=2, indwhite(2)=4, indwhite(3)=6 etc. e indblack(1)=1, indblack(2)=3, indblack(3)=5 etc.
 |
Precisamos ainda de vetores que carreguem informação a respeito da estrutura de primeiros vizinhos. Assim temos o vetor neighbor(i,j) de maneira que neighbor(1,1)=6, neighbor(1,2)=2, neighbor(1,3)=31, neighbor (1,4)=7 expressam os vizinhos nas 4 direções bi-dimensionais no sítio 1 da rede completa. Estruturas análogas são desenvolvidas para as redes black e white.
A subrotina também define um array associado com as transformadas de Fourier do campo, o indphase(msite,imode). A idéia é armazenar variáveis inteiras que funcionam como ponteiros para locais de memória onde estão calculadas as fases de Fourier. Para entender melhor este procedimento, vamos considerar uma rede bidimensional com 4 sítios em cada direção. O índice imode representa os modos de Fourier que são calculados. Neste código calculamos somente os modos com todas as componentes de Fourier positivas. Assim, o array indphase contém
e assim sucessivamente até imode=8, representando o oitavo modo de Fourier calculado. Conforme veremos na subrotina transform, este array é utilizado para calcular as transformadas de Fourier do campo nos modos selecionados.
A subrotina transform calcula as transformadas de Fourier do campo, definidas a partir de (3.6). Como exemplo, vamos considerar novamente d=2 e N=4. Neste caso o modo zero é definido como
onde o índice isite percorre todos os sítios da rede. No
código este modo é expresso como
![]() onde
onde
e
com o índice 1 relacionado com a simetria interna do modelo, neste caso 1.
A subrotina accumulate acumula os observáveis preliminares. Para
entender o seu funcionamento lembremo-nos que os observáveis do modelo
são expressos por uma integração funcional que pode ser entendida como
uma soma dos observáveis em cada uma das infinitas possibilidades de
configuração dos campos, ponderada pelo ``peso estatístico''
![]() .
Os algoritmos de geração dos campos são efetuados
nas rotinas cluster e sweeper e garantem uma coleção de
configurações com distribuição dada pelo peso certo.
.
Os algoritmos de geração dos campos são efetuados
nas rotinas cluster e sweeper e garantem uma coleção de
configurações com distribuição dada pelo peso certo.
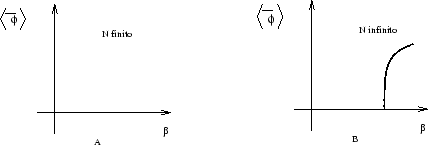
Em redes finitas o valor esperado do campo é nulo para qualquer valor de beta mesmo em modelos onde há quebra espontânea de simetria (QES). O mecanismo de transição de fases aparece somente no limite do contínuo conforme a figura (B.5).
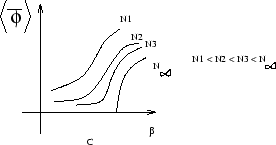
Gostaríamos de obter um comportamento similar a (B.5.b) já em redes finitas. Porém sabemos que nestes modelos quando se introduz uma fonte externa temos apresentado na figura (B.6) no limite da fonte externa tendendo a zero.
 |
A idéia então é forçar um comportamento tipo (B.6) mesmo sem fontes
externas. Lembrando que as fontes externas introduzem no sistema uma direção
preferencial, podemos fixar uma direção de quebra de
simetria (por convenção a última) através do mecanismo que denominamos
back rotation. Através dele rodamos
![]() na direção do último eixo de simetria interna. Desta maneira um modelo
com simetria SO(3) por exemplo passa a ter simetria SO(2).
na direção do último eixo de simetria interna. Desta maneira um modelo
com simetria SO(3) por exemplo passa a ter simetria SO(2).
Além disso, fazemos um random twist, para ocupar melhor o espaço
de configurações e desta maneira melhorar a função de
autocorrelação. Por exemplo, para modelos com simetria SO(2), fazemos
uma rotação ![]() de todos os campos juntos em cada configuração.
de todos os campos juntos em cada configuração.
A rotina rotator executa o back rotation e o random twist.